

■ Databases
데이터베이스(database)는 대용량의 데이터에서 원하는 정보를 빠르고 효율적으로 얻어내는 방법을 연구하는 분야입니다. 최근에는 빅데이터(Big Data)에 대한 관심으로 인해 더욱 주목받고 있는 핵심 기술이기도 합니다. 특히 본 연구실에서는 대용량의 데이터가 저장되어 있을 때, 사용자가 요청한 다양한 형태의 질의(query)를 빠르게 처리하는 기술을 집중적으로 연구하고 있습니다. 이를 위해 원하는 데이터를 빠르게 찾기 위한 색인(index) 기술도 같이 연구하고 있습니다. 데이터베이스 관리 시스템(database management system, DBMS)은 현재 대부분의 상용 정보 시스템(information system)에서 거의 필수적으로 사용되는 핵심 시스템 중 하나입니다. 따라서 데이터베이스에 대한 연구경험은 추후 어떤 소프트웨어를 개발하거나 연구하든지 매우 중요한 핵심적인 역량으로 인정받고 있으며, 많은 기업과 연구소에서 소프트웨어 관련 인력 채용시 가장 많이 찾는 경력 중 하나이기도 합니다.

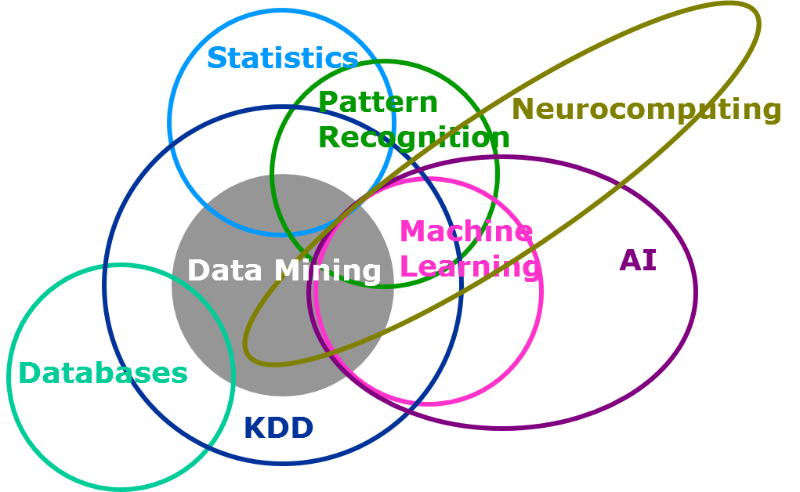
■ Data Mining
데이터 마이닝(data mining)은 데이터에서 쉽게 예측할 수 없는 패턴이나 정보를 사람의 개입없이 자동으로 추출하는 방법을 연구하는 분야입니다. 데이터 마이닝은 통계학, 인공지능, 데이터베이스 등 다양한 분야의 기술이 함께 사용되는 분야이기도 합니다. 데이터 마이닝에는 크게 다음과 같은 세부 연구분야갸 있습니다: (1) 데이터에서 빈번히 발생하는 패턴을 찾는 빈발 패턴 마이닝(frequent pattern mining), (2) 데이터를 유사한 데이터끼리 자동으로 그룹화하는 클러스터링(clustering), (3) 어떤 데이터가 어떤 종류에 속하는 데이터인지를 자동으로 판단하는 분류(classification), (4) 지금까지 관측된 데이터를 사용하여 알려지지 데이터를 예측하는 예측(prediction), (5) 지금까지 관측된 데이터 중 다른 데이터와는 다른 특이한 데이터를 찾는 이상치 발견(outlier detection) 등이 있습니다. 본 연구실에서는 이들 중 빈발 패턴 마이닝, 클러스터링, 예측을 집중적으로 연구하고 있으며, 특히 빅데이터 처리 플랫폼에서 효율적으로 수행 가능한 데이터 마이닝 알고리즘을 개발하는 것을 목표로 하고 있습니다.
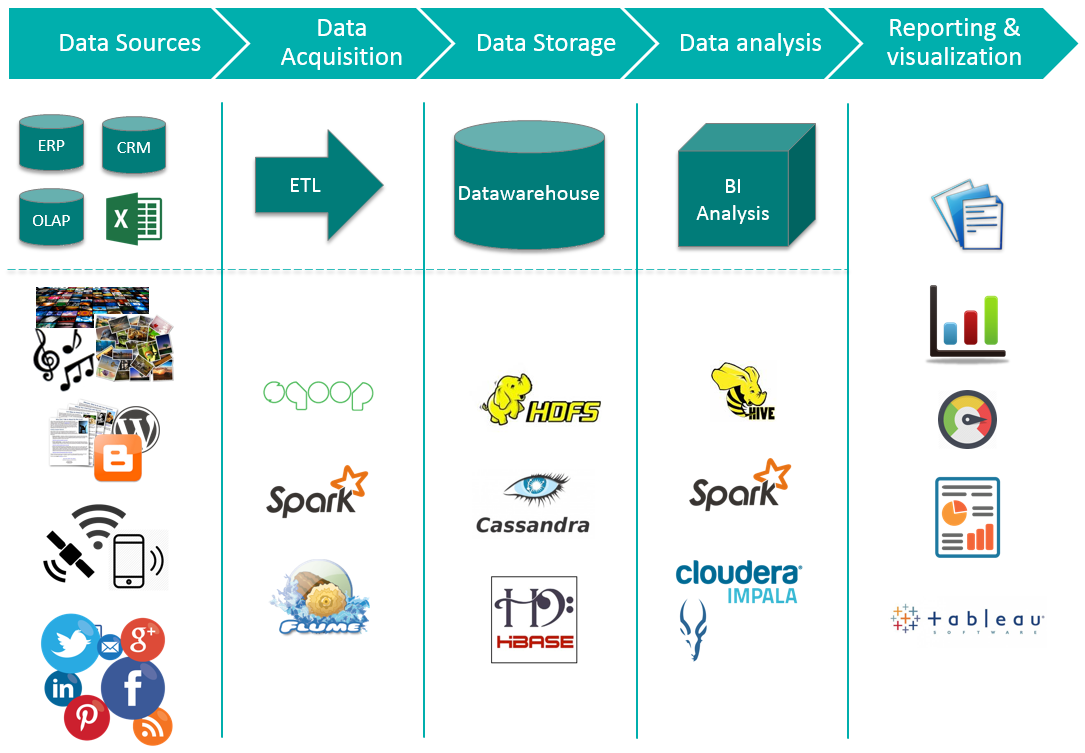
■ Big Data
빅데이터(Big Data)는 최근 들어 데이터의 양이 급증하는 한편 데이터의 증가 속도가 매우 커지고 형태도 매우 다양해지면서, 기존의 기술로는 제대로 분석할 수 없는 대규모 데이터에 대한 분석 기술을 연구하는 분야입니다. 특히 빅데이터는 대규모 데이터를 처리하기 위해 다수의 컴퓨터를 네트워크로 연결한 컴퓨터 클러스터(cluster)를 사용하는 것이 일반적입니다. 본 연구실에서는 이러한 컴퓨터 클러스터 환경에서 데이터베이스 기술에 기반하여 빅데이터를 빠르게 처리하는 기술을 연구하고 있습니다. 이러한 맥락에서 데이터베이스에 대한 연구와 마찬가지로 빅데이터에 대한 다양한 형태의 질의를 빠르게 처리하는 것을 집중적으로 연구하고 있습니다. 한편 현재 빅데이터를 분석하기 위한 도구로서 Hadoop, Spark, NoSQL 등과 같이 새로운 기술에 기반한 빅데이터 처리 플랫폼들이 활발히 개발되고 있습니다. 본 연구실에서는 이러한 빅데이터 처리 플랫폼의 성능 개선 및 빅데이터 처리 플랫폼에 적용 가능한 새로운 데이터 처리 기술 개발도 중요한 목표로 하고 있습니다.
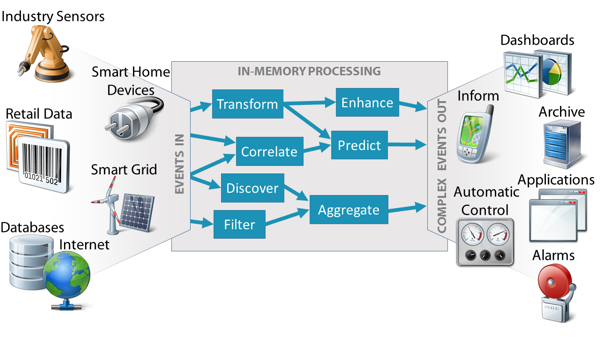
■ Data Streams
데이터 스트림(data stream)은 매우 빠른 속도로 계속해서 유입되는 데이터에 대한 분석 기술을 연구하는 분야입니다. 데이터 스트림의 대표적인 예로는 각종 센서 데이터(예: 온도, 습도, 압력, 조도), 온라인 구매 데이터, 네트워크 트래픽(traffic) 데이터, 사물 인터넷(IoT) 데이터, SNS 데이터(예: Facebook, Twitter) 등이 있습니다. 이러한 데이터는 계속해서 빠르게 유입되기 때문에 이러한 데이터로부터 손실없이 유용한 정보를 얻기 위해서는 무엇보다 데이터를 실시간으로 빠르게 처리하는 것이 중요합니다. 본 연구실에서는 다수의 데이터 스트림이 동시에 유입될 때, 이들을 분석하기 위해 사용자가 요청한 다양한 분석 질의들을 다수의 컴퓨터를 활용하여 실시간으로 처리하는 기술을 연구하고 있습니다. 또한 빅데이터와 마찬가지로 대규모 데이터 스트림을 처리하기 위해 Storm, Spark Streaming, Samza 등 다양한 데이터 스트림 처리 플랫폼들이 활발히 개발되고 있습니다. 본 연구실에서는 이러한 데이터 스트림 처리 플랫폼에 적용 가능한 새로운 데이터 스트림 처리 기술 개발도 진행하고 있습니다.
■ Scientific Data Processing
최근 다양한 과학분야(물리, 천문, 생명, 의학 등)에서 측정장비 및 시뮬레이션 기술이 크게 발전하면서, 2차원 혹은 다차원의 배열(array) 형태를 가진 관측 데이터가 하루에도 수 GB ~ TB씩 발생하고 있습니다. 이러한 데이터는 빅데이터의 새로운 한 형태로 볼 수 있습니다. 배열 데이터는 원소 간의 위치 관계가 존재하는 등, 데이터베이스 분야에서 그동안 전통적으로 다뤄왔던 데이터와는 특성이 매우 다르며 그에 따라 지금까지와는 다른 새로운 처리 기술을 사용해야 합니다. 본 연구실에서는 2차원 혹은 다차원의 대규모 배열 데이터에 대한 다양한 형태의 질의를 효율적으로 처리하는 기법을 연구하고 있습니다. 보다 구체적으로 배열 데이터에서 숨겨진 패턴을 찾아내는 배열 데이터 마이닝과, 배열에 대한 질의를 병렬적으로 처리하는 기법을 연구 중입니다. 이를 통해 Hadoop이나 SciDB와 같은 병렬 처리 플랫폼을 사용하여 배열 데이터에 대한 질의를 빠르게 처리하는 고성능 질의 처리기를 구현하는 것이 최종 목표입니다. 이러한 연구를 통해 다양한 과학분야와 협업이 가능할 것으로 기대합니다.
국가
대한민국
소속기관
숙명여자대학교 (학교)
연락처
02-2077-7583 http://cs.sookmyung.ac.kr/~kylee/dilab/
책임자
이기용 kiyonglee@sookmyung.ac.kr