

분야
정보/통신
발행기관
정보통신기획평가원
발행일
2019.04.25
URL
2019년 1월 구글 딥마인드는 스타크래프트2 게임 인공지능, ‘알파스타’를 공개하고, 프로게이머와의 대결에서 10승 1패의 성적을 거뒀다. 특히, 알파스타는 알파고와는 장르가 판이하게 다른 게임이기 때문에, 알파스타의 성공은 곧 장기 계획과 실시간 의사결정 문제 해결에 큰 도움이 될 것이다. 알파스타의 인공지능 알고리즘은 리플레이 데이터의 지도학습과 알파스타 리그로 명명된 자체 대결을 통해 프로게이머 수준을 달성했다.
스타크래프트2 인공지능 알파스타(AlphaStar)의 부상
지난 2016년 3월 구글 딥마인드가 개발한 바둑 인공지능 알파고는 세계 최정상 바둑기사 이세돌 9단에 맞서 4승 1패의 성적을 거뒀다. 전문가들은 대국에 앞서 바둑 게임의 무한대에 가까운 경우의 수로 인해 인공지능이 바둑을 정복하기에는 십 년이 넘게 걸릴 것이라고 예측했었다. 그러나 알파고는 이러한 예측을 보기 좋게 뒤엎었다. 현대 인공지능의 부흥을 이끈 심층학습(Deep Learning)과 보상으로부터 배우는 강화학습(Reinforcement Learning), 그리고 턴 방식의 보드게임에서 주로 활용됐던 몬테-카를로 트리 탐색(Monte-Carlo Tree Search) 알고리즘이 그 원동력이었다.
당시 딥마인드는 이세돌 9단과의 대국 이후 다음 목표로 스타크래프트2 인공지능 개발을 천명했다. 스타크래프트2는 바둑과 판이하게 다른 게임 속성을 지니고 있기 때문에, 이 언급에 대한 기대와 우려가 공존했다. 그 구체적인 차이점은 다음 [표 1]과 같다.
| 구 분 | 바 둑 | 스타크래프트2 |
|---|---|---|
| 장르 | 보드게임 | 실시간 전략 시뮬레이션 |
| 게임 진행 | 턴 방식 | 실시간 명령 |
| 게임 공간 | 19×19 격자 공간 (총 361개) |
한 스텝의 행동 기준 108가지의 조합 공간 |
| 소요 시간 | 1 ∼ 4시간 | 10분 ∼ 1시간 |
| 상대방의 상황 | 모두 공개 | 정찰을 통해 습득 |
※ 주 : 소요 시간의 경우 극단적인 상황을 제외한 일반적인 것을 가정함
[표 1]과 같이 스타크래프트2는 바둑과 전혀 다른 영역의 게임이다. 이에 따라 알파고의 성공이 곧 스타크래프트2의 성공으로 이어질 수 있을까에 대한 의구심도 많이 존재했다. 넓은 게임 공간(Problem Space), 불완전한 정보(Imperfect Information), 실시간으로 변경되는 전략(Real-time Strategy) 등 많은 난제가 도사리고 있었기 때문이다. 또한 스타크래프트2는 컴퓨터를 활용한 게임이기 때문에 인간과의 대결에서 공정성 논란 역시 불거졌다. 혹자는 스타크래프트2 인공지능의 분당 행동 수1(Action Per Minute)를 제한하기 위해 로봇 팔로 직접 마우스와 키보드를 조작해야 한다고도 주장했다.
스타크래프트2 인공지능 개발 환경의 공개
스타크래프트2 인공지능을 기대와 우려가 공존하는 시선으로 바라보는 가운데, 딥마인드는 2017년 8월 자사 홈페이지를 통해 스타크래프트2 인공지능 개발에 대한 동향을 알렸다.2 딥마인드는 스타크래프트2 인공지능 개발을 위대한 도전(Grand Challenge)으로 선언하며 스타크래프트2 개발사인 블리자드 엔터테인먼트와 인공지능 개발 도구인 SC2LE(StarCraft Ⅱ Learning Environment)를 공개했다. 동시에 6만 5천 개의 게임 리플레이 데이터를 제공하여, 심층 강화학습(Deep Reinforcement Learning)을 활용한 초기 결과를 공개했다.3 그러나 초기 결과는 스타크래프트2 인공지능의 목표인 1대1 경기에서 성능이 매우 좋지 않았다.
딥마인드는 1년 6개월이 지난 2019년 1월 자사의 블로그에 알파스타로 명명된 스타크래프트2 인공지능을 공개했다. 그 성능을 먼저 테스트하기 위한 스타크래프트2 프로게이머와의 대결 결과로 주위의 이목을 끌었다. 첫 번째 경기는 유럽의 스타크래프트2 프로게임단인 ‘Team Liquid’의 프로게이머 TLO가 펼쳤다. TLO의 상대인 알파스타는 스타크래프트2의 세 종족4 중 프로토스에 최적화된 인공지능이었다. TLO의 주 종족은 저그였으나, 프로토스를 선택했기에 경기에서는 일종의 페널티가 부여됐다.5 결과는 알파스타가 TLO에게 5전 전승이었다. TLO는 경기를 마치고 “마치 사람처럼 조작하는 것 같다”라는 평을 내렸다. 이후 알파스타가 도전한 프로게이머는 TLO와 같은 팀 소속의 프로토스 게이머인 MaNa였다. TLO가 주 종족을 선택하지 않았다는 점에서 MaNa와의 대결은 알파스타의 성능을 가늠해 볼 수 있는 측정도구였다. MaNa와의 대결 결과는 놀랍게도 알파스타가 5전 전승을 거뒀다. 정상급 프로게이머와 대결해 승리한 알파스타는 과거 알파고의 전철을 밟아 가며 또 하나의 역사를 만들고 있다는 것이다.
스타크래프트2 인공지능 개발의 도전과제
그렇다면 알파스타의 원동력은 무엇일까? 스타크래프트2 인공지능 개발을 천명하고 채 3년이 지나지 않은 시점에서 알파스타라는 결과물이 나온 것도 놀랍다. 그 이유는 스타크래프트2가 바둑과는 전혀 다른 방식의 게임이고, 다양한 도전과제가 존재했기 때문이다. 이 도전과제를 요약하면 다음 [표 2]와 같다.
| 도전과제 | 내 용 |
|---|---|
| 게임 이론 | ? 가위-바위-보 게임과 같이 하나의 최상의 전략은 없음 |
| 불완전한 정보 | ? 상대방의 정보는 정찰이라는 수단을 통해 획득 ? 스타크래프트2의 전략은 상대방의 정보를 바탕으로 자신의 전략을 수정 및 고도화하는 방향으로 진행 |
| 장기 계획 | ? 실세계의 문제와 같이 원인과 결과가 즉각적으로 반영되지 않음 |
| 실시간 제어 | ? 연속적인 동적 조작을 통해 게임이 진행됨 ? 측정 기준으로는 분당 행동 수(Actions Per Minutes, APM)가 있음 |
| 넓은 조작 공간 | ? 하나의 행동을 결정하기 위해 산술적으로 약 108가지의 조합 공간을 가짐 ? 일반적으로 한 스텝당 유효한 일련의 행동을 선정해야 함 |
※ 출처 : Deepmind(2019.1.), “AlphaStar : Mastering the Real-Time Strategy Game StarCraft II”.
https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
사실 게임은 전통적으로 인공지능이 필요한 분야다. 게임이 소위 컴퓨터와의 대결을 지원해야 하기 때문이다. 일반적인 게임 인공지능 개발방법은 규칙 기반(Rule-based) 접근이다. 스타크래프트2를 예로 들어보면, 먼저 인공지능 에이전트는 지속적으로 상대방을 정찰하고, 관측된 내용을 바탕으로 건물 설립과 전투 유닛 생산을 하는 방식이다. 그러나 이러한 접근방법에는 입력된 규칙에서 벗어난 행위에 대해서는 능동적인 대처가 어렵다. 따라서 인공지능 에이전트의 성능을 높이기 위해 더 많은 정보를 주는 것이 일반적이다. 예를 들면, 인공지능 에이전트가 정찰을 하지 않아도 상대방이 무엇을 하는지 볼 수 있는 권한을 부여하는 것이다. 이러한 방식의 인공지능은 인간과 동등한 조건이 아니기 때문에 엄밀한 의미에서는 인공지능이라고 보기 어렵다.
인공지능 개발에 있어 스타크래프트2와 바둑의 차이점
딥마인드가 스타크래프트2 인공지능을 개발하는 방식은 철저히 인간과 공평한 것을 전제로 한다. 이러한 환경에서 알파스타가 프로게이머에 완승을 했다는 사실은 참으로 놀라운 일이 아닐 수 없다. 알파스타의 인공지능에 본격적으로 들어 가기 앞서 알파고와는 어떠한 차이점이 있는지 살펴보자.
| 구 분 | 알파고 Lee | 알파스타 |
|---|---|---|
| 학습 데이터 | 16만 건의 대국 | 80만 건 이상의 리플레이 데이터 |
| 입력 (inputs) |
48개의 특성으로 나눠진 기보 (예 – 흑돌, 백돌, 빈칸 위치, 단수, 축, 꼬부림 등) |
PySC26를 활용한 이미지 데이터 (예 – 현재 시야, 건물, 유닛 등) |
| 출력 (outputs) |
착수 가능 지점의 확률, 승리할 확률 |
일련의 행동(10개 ~ 26개), 승리할 확률 |
| 학습 방법 | 기보를 통한 지도학습과 자체 대결을 통한 강화학습 |
리플레이 데이터의 지도학습과 자체 대결을 통한 강화학습 |
| 학습 구조 (architecture) |
합성곱신경망, 몬테-카를로 트리 탐색 (MCTS) |
합성곱신경망, 장단기기억(LSTM), 어텐션, 포인터네트워크 등 |
※ 주 : 알파고의 버전은 2016년 이세돌 9단과 대결했던 버전을 기준으로 함(AlphaGo LEE)
※ 출처 : Vinyals, Oriol, et al(2017), “Starcraft ii: A new challenge for reinforcement learning”, arXiv preprint arXiv:1708.04782에서 재정리
[표 3]을 보면 알파고와 알파스타의 인공지능은 큰 틀에서 유사한 방식으로 학습이 진행됐다. 알파고와 알파스타는 각각 바둑과 스타크래프트2 게임 전문가의 기보와 리플레이 데이터를 바탕으로 1차적인 지도학습(Supervised Learning)을 수행했다. 이후 자체 대결(Self-play)을 통한 강화학습으로 성능 향상을 꾀했다. 그러나 데이터의 입력 및 출력, 그리고 학습에 활용된 인공신경망 구조에서는 상당한 차이점이 보인다. 이것은 두 게임의 속성이 그만큼 다르다는 것을 보여 준다.
알파스타 인공지능 개발과정 - 심층학습을 중심으로
먼저 알파스타의 입력은 이미지다. [그림 1]은 스타크래프트2 인공지능 개발 환경인 SC2LE에서 제공하는 것으로, 실제 게임 화면에서 다양한 특성을 추출하여 RGB 이미지를 생성한다. 특성맵은 현재 게임화면의 아군과 적군의 위치, 건물의 위치, 유닛의 체력, 시야 등과 미니맵의 정보 등으로 구성된다.
알파스타의 출력은 일련의 명령이다. 예를 들면, 일꾼 유닛에게 자원을 채취하거나 건물을 짓는 행동, 정찰기를 이동하는 명령, 전투 유닛이 건물을 공격하는 명령 등이 있다. 딥마인드는 이 명령의 길이가 10개에서 26개 정도로 가변적이라고 밝혔다. 이 명령의 예시는 [그림 2]와 같이 표현할 수 있다.

<그림 1> 알파스타의 입력 예시
※ 출처 : Vinyals, Oriol, et al(2017), “Starcraft ii: A new challenge for reinforcement learning”, arXiv preprint arXiv: 1708.04782.
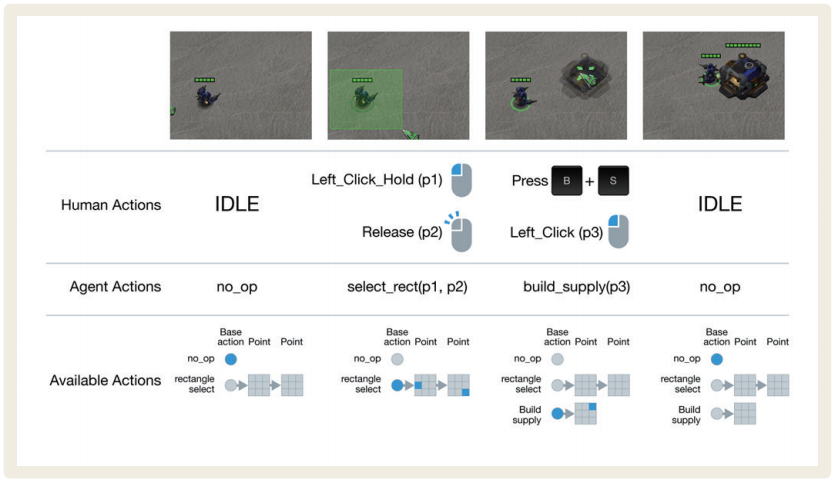
<그림 2> 알파스타의 출력 예시
※ 출처 : Deepmind(2019.1.), “AlphaStar: Mastering the Real-Time Strategy Game StarCraft II”.
https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
알파스타는 초기버전을 기준으로 위와 같은 입력과 출력을 활용한 지도학습을 수행했다. 연구 초기에는 이미지 인식에 최적화된 합성곱신경망이 주로 사용됐으나, 출력 값이 일종의 문자열과 유사하므로 기계번역이나 언어기술에 활용되는 신경망이 추가된 것으로 추정된다.
알파스타 인공지능 개발과정 – 알파스타 리그
알파스타 리그로 명명된 알파스타의 자체 대결 알고리즘은 알파스타의 백미다. 지도학습의 결과물로 생성된 최초의 알파스타 에이전트는 스타크래프트 배틀넷 기준 골드 수준으로 초심자를 벗어난 게이머 정도로 볼 수 있다. 이것을 기반으로 자체 대결을 통해 얻은 최후의 인공지능 에이전트가 정상급 프로게이머와 대결해서 승리한 것이고, 바로 알파스타 리그가 그 역할을 했다. [그림 3]을 보면 지도학습과 알파스타 리그 이후의 성능이 얼마나 차이가 나는지 확인할 수 있다. 그래프의 각 점은 알파스타 리그에서 자체 대결을 위해 생성된 인공지능 에이전트이고, y축은 MMR(Match Making Rate)7이라는 지표다.
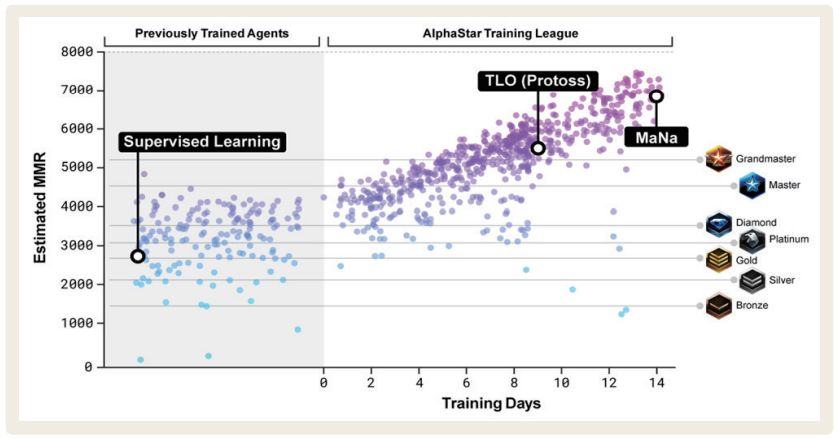
<그림 3> 알파스타의 성능
알파스타 리그는 구글의 심층학습 전용 연산처리장치인 TPU(Tensorflow Processing Unit) 16대를 활용해 약 14일간 진행됐다. 이 기간 동안 진행된 게임 시간을 계산해 보면 약 200년에 해당한다. 약 80만 건의 리플레이 데이터와 200년 정도의 자체 대결을 통해 고도화된 알파스타는 결국 정상급 프로게이머의 대결에서 승리하게 된다. 양적으로 봤을 때는 자연스레 수긍이 가는 부분이 있지만, 어떻게 이것이 가능케 됐는지에 대해서는 새삼 놀라울 수밖에 없다. 딥마인드는 ‘어떻게?’에 대한 해답을 논문을 통해 발표할 예정이나, 아직은 그 구체적인 윤곽이 드러나지 않은 상황이다.
알파스타의 인공지능 알고리즘
제한된 정보이지만 딥마인드가 자사의 블로그에 게시한 글에 따르면 12종의 인공지능 알고리즘이 활용됐다. [표 4]는 알파스타에 활용된 인공지능 알고리즘의 목록이다.
| 구 분 | 알 고 리 즘 |
|---|---|
| 리플레이 데이터 학습 | Transformer, LSTM, Auto-regressive policy head, Pointer network, Centralised value baseline |
| 알파스타 리그 학습 | Population-based reinforcement learning, Multi-agent reinforcement learning, Off-policy actor-critic, Experience replay, Self-imitation learning, Policy distillation, Nash distribution of the league |
※ 출처 : Deepmind(2019.1.), “AlphaStar: Mastering the Real-Time Strategy Game StarCraft II”.
https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
리플레이 데이터의 지도학습 알고리즘의 특징은 정보를 저장하는 메모리 모델과 시계열 데이터 예측에 활용되는 알고리즘이 활용됐다. 스타크래프트2의 도전과제에서도 살펴 봤듯이 인공지능 개발에는 장기 계획과 실시간 조작이 필요하다. 정보를 저장하기 위한 Transformer, LSTM(Long Short Term Memory)이 활용됐으며, 행동의 수를 유동적으로 산출하기 위해 Pointer Network가 활용된 것으로 추측된다. 특히 기계번역이나 언어 모델의 분야에서 많이 활용되는 기법들이 적용되었다는 점이 게임의 특성을 잘 반영했다고 본다.
알파스타 리그에서는 다수의 에이전트의 대결을 통해 고도화하는 강화학습이 주로 활용됐다. 특히 스타크래프트2는 가위-바위-보 게임과 같은 속성을 가지고 있기 때문에 가장 좋은 하나의 전략은 없다. 특정 전략이 다른 전략과 천적관계가 있을 수 있다는 것이다. 딥마인드는 알파스타 리그의 각 에이전트에 각기 다른 목적을 부여하여 알파스타를 고도화하는 방법을 꾀했다. 예를 들면 에이전트001에는 에이전트002만을 이기기 위한 목적을 부여하며, 에이전트003에는 모든 에이전트에 대해 승리하기 위한 목적을 부여하는 것이 있다.
마지막으로 알파스타에 활용된 인공지능 알고리즘의 특징은 계산적인 효율을 염두해 두었다는 것이다. 과거 알파고는 30~40억 원 수준의 컴퓨터 클러스터를 활용했다는 점에서 공정성에 대한 논란이 불거졌었다. 딥마인드는 계산적인 측면에서 자원을 최대한 적게 활용하는 기법을 다수 활용한 것으로 추정된다. 실제로 학습에 활용된 자원도 TPU 16장으로 대규모 컴퓨터라고 보기엔 무리가 있다. 또한 프로게이머와의 대결에서도 데스크톱 GPU 한 장을 활용했다.
시사점
아직 알파스타의 논문이 공개되지 않아 더 구체적으로 살펴보기에는 어려움이 있으나, 지금까지의 결과를 바탕으로 추측컨대 가히 인공지능의 ‘Grand Challenge’를 달성했다고 볼 수 있을 것이다. 알파스타는 알파고 못지않은 위대한 업적이다. 특히 스타크래프트2는 상당한 복잡도를 갖고 있기 때문에 사실 도전한다는 자체만으로도 의미가 있다. 하물며 프로게이머와 대결해 압도적으로 승리했다는 사실은 그 자체만으로도 인공지능 역사에 굵직한 획을 그은 사건이라고 생각한다.
알파스타에 활용된 인공지능 알고리즘의 면면을 살펴보면 대부분 최신의 연구결과다. 어떻게 보면 알파스타를 개발하기 위한 목적으로 연구를 수행했다고도 볼 수 있을 정도다. 알파고 대국 이후 3년이 채 안 된 시점에서 전혀 다른 Grand Challenge급의 문제를 해결한 딥마인드의 저력이 새삼 놀라울 따름이다.
딥마인드는 어떻게 알파스타를 개발할 수 있었을까? 그 해답은 인공지능 연구의 프로세스에서 쉽게 찾아볼 수 있다. 현재 인공지능 연구는 전형적인 오픈 사이언스(Open Science) 방식으로 진행되고 있다. 인공지능 연구자는 연구 주제나 참신한 아이디어의 선점을 위해 arXiv를 활용하고, 그것을 github 같은 SW 저장소를 통해 물리적인 소스코드로 증명한다. 또한 유수의 인공지능 학회에서 산출되는 학술논문집(Proceedings)은 연구결과의 신속한 공유를 촉진한다. 인공지능은 이러한 특성으로 인해 그 발전 속도가 체감할 수 없을 정도로 빠른 것이다. 딥마인드는 또한 스타크래프트2 인공지능 개발 도구인 SC2LE를 공개함으로써 많은 연구자가 진입할 수 있는 여건을 조성했다. 이러한 환경이 맞물려 얻어진 결과가 알파스타라고 할 수 있겠다.
비록 알파스타는 스타크래프트2라는 게임에서 인공지능을 개발하는 것을 목표로 했으나 이것이 시사하는 바는 매우 크다. 게임과 같이 목표가 분명하고, 풍부한 데이터를 수급할 수 있는 분야는 많지 않다. 그러므로 게임 인공지능 개발을 통해 궁극의 인공지능 개발에 다가가는 접근이 무엇보다 참신하다고 볼 수 있다. 실제로 알파스타에 활용된 자체 대결 도구인 알파스타 리그는 그 활용도가 매우 높다. 서로 장단점을 갖는 에이전트들 간의 목적지향적인 대결을 통해 단점을 줄이고 장점을 극대화하는 접근이기 때문이다. 이것은 곧 인공지능을 활용한 시스템의 안전성과도 결부되는 것이다. 또한 스타크래프트2의 도전과제 중 하나인 장기 계획은 날씨 예측이나 기후 변화 등에 접목될 가능성이 크다. 실시간 전략게임으로써의 인공지능의 활용은 국방 분야의 워게임에도 쉽게 반영될 것이라 기대된다.
- 1 실시간 전략 게임에서 명령을 내리는 빠르기를 측정하는 것으로 1분당 명령 수(예, 유닛 선택, 이동 명령 등)로 측정하며, 일반적으로 키보드와 마우스의 입력수로 산정됨.
- 2 Deepmind(2017.8.9.), “DeepMind and Blizzard open StarCraft Ⅱ as an AI research environment”. https://deepmind.com/blog/deepmind-and-blizzard-open-starcraft-ii-ai-research-environment/
- 3 Vinyals, Oriol, et al(2017), “Starcraft ii: A new challenge for reinforcement learning”, arXiv preprint arXiv: 1708.04782
- 4 테란, 저그, 프로토스의 3가지 종족.
- 5 프로게이머는 일반적으로 하나의 종족에 특화되어 있으며, 자신의 주 종족이 아닌 타 종족을 선택할 경우 실력의 편차가 상당히 있으나, 프로게이머의 특성상 타 종족을 선택하더라도 일반인의 실력보다는 월등함.
- 6 PySC2는 스타크래프트2 개발사인 블라자드 엔터테인먼트와 딥마인드가 제공하는 도구로 게임 데이터 취득 및 조작을 지원하는 API임.
- 7 MMR은 서로 비슷한 실력의 유저를 대결시키기 위한 점수로, 높을수록 게임 실력이 높음을 의미하며 일반적으로 1,000점 이상 차이가 나는 경우 압도적인 실력 차이가 존재한다고 볼 수 있음.
https://spri.kr/posts/view/22614?code=industry_trend
추천 리포트
-
[코센리포트] 러시아-우크라이나 전쟁으로 인한 에너지전환
-
[학회보고서] 19회 국제 컴퓨터 비전 학회
-
[코센리포트] 마인드테크와 인공지능
-
[코센리포트] 바이오차를 이용한 온실가스 배출 저감
-
[코센리포트] 유럽 대화형 인공지능의 현재와 미래
-
[코센리포트] 인공지능과 비디오게임
-
[코센리포트] Tiny AI(극소형 인공지능) 기술 및 시장 동향
-
[코센리포트] 인간 중심 인공지능 연구 동향
-
[코센리포트] 설명 가능한 인공지능 기술(Explainable AI)에 의한 인공지능 응용 시장의 향후 변화
-
[코센리포트] 지속가능한환경을 위한 AI 기술 활용 동향
-
리포트 평점
해당 콘텐츠에 대한 회원님의 소중한 평가를 부탁드립니다. -
0.0 (0개의 평가)