ntroduction
Artificial intelligence is a field of computer science that studies how to solve problems efficiently by simulating human cognition, thinking, memory, and learning.
The Artificial Intelligence Lab. was founded in 1995. The AI Lab is under the department of computer engineering at Dongguk University in Seoul, Korea and conducting researches on mainly on machine learning and natural language processing.
With huge increasing interest in AI, the lab has carried out a number of projects with AI topics in cooperation with related industries. We suggest you to have a look on our outcomes of researches and projects by browsing our web page.
Research Areas
Machine learning
Machine learning is the subfield of computer science that gives computers the ability to learn without being explicitly programmed. Evolved from the study of pattern recognition and computational learning theory in artificial intelligence, machine learning explores the study and construction of algorithms that can learn from and make predictions on data. Machine learning tasks are typically classified into three broad categories, depending on the nature of the learning “signal” or “feedback” available to a learning system. Lately, main sub topics of machine learning are data mining and deep learning.
-
Supervised learning: The computer is presented with example inputs and their desired outputs, given by a “teacher”, and the goal is to learn a general rule that maps inputs to outputs.
-
Unsupervised learning: No labels are given to the learning algorithm, leaving it on its own to find structure in its input. Unsupervised learning can be a goal in itself (discovering hidden patterns in data) or a means towards an end (feature learning).
-
Reinforcement learning: A computer program interacts with a dynamic environment in which it must perform a certain goal (such as driving a vehicle or playing a game against an opponent). The program is provided feedback in terms of rewards and punishments as it navigates its problem space.
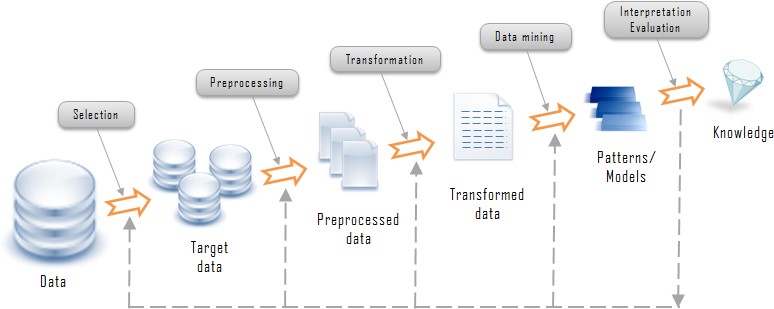
Data Mining: Data mining is the computational process of discovering patterns in large data sets involving methods at the intersection of artificial intelligence, machine learning, statistics, and database systems. The overall goal of the data mining process is to extract information from a data set and transform it into an understandable structure for further use. Data mining involves six common classes of tasks.
-
Anomaly detection (Outlier/change/deviation detection): The identification of unusual data records, that might be interesting or data errors that require further investigation.
-
Association rule learning (Dependency modelling): Searches for relationships between variables. For example, a supermarket might gather data on customer purchasing habits. Using association rule learning, the supermarket can determine which products are frequently bought together and use this information for marketing purposes. This is sometimes referred to as market basket analysis.
-
Clustering: is the task of discovering groups and structures in the data that are in some way or another “similar”, without using known structures in the data.
-
Classification: is the task of generalizing known structure to apply to new data. For example, an e-mail program might attempt to classify an e-mail as “legitimate” or as “spam”.
-
Regression: attempts to find a function which models the data with the least error.
-
Summarization: providing a more compact representation of the data set, including visualization and report generation.
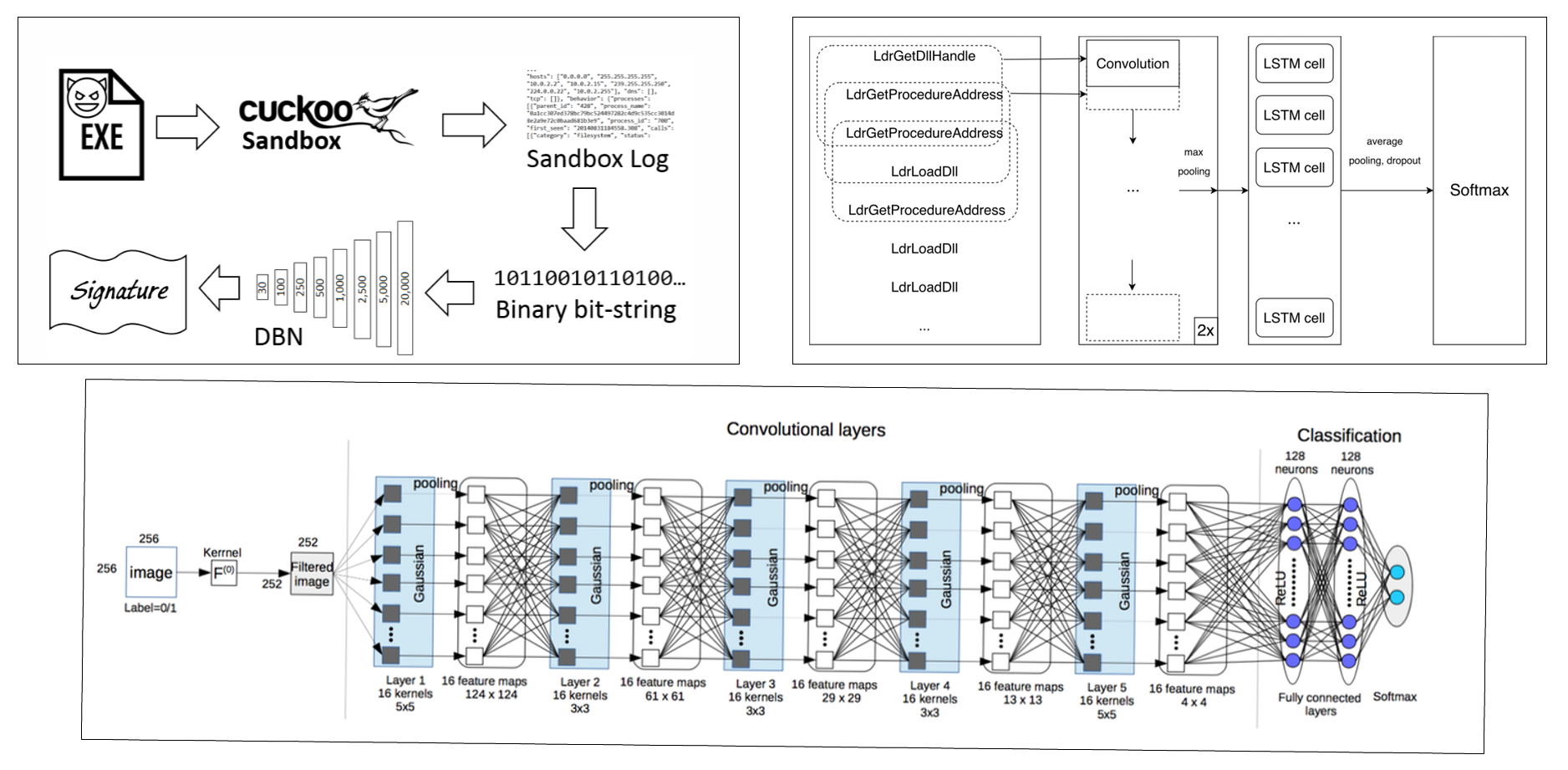
Deep Learning: is a branch of machine learning based on a set of algorithms that attempt to model high level abstractions in data. An observation (e.g., an image) can be represented in many ways such as a vector of intensity values per pixel, or in a more abstract way as a set of edges, regions of particular shape, etc. Some representations are better than others at simplifying the learning task. Various deep learning architectures such as deep neural networks, convolutional deep neural networks, deep belief networks and recurrent neural networks have been applied to fields like computer vision, automatic speech recognition, natural language processing, audio recognition and bioinformatics where they have been shown to produce state-of-the-art results on various tasks.
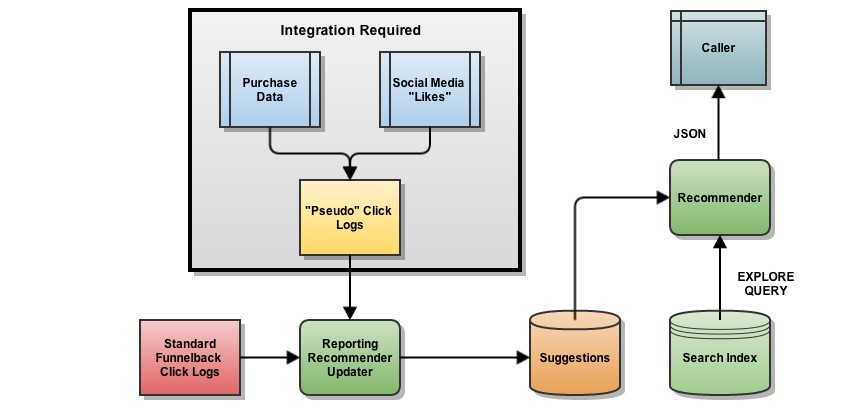
Recommender System: Recommender systems or recommendation systems are a subclass of information filtering system that seek to predict the “rating” or “preference” that a user would give to an item. Recommender systems have become increasingly popular in recent years, and are utilized in a variety of areas including movies, music, news, books, research articles, search queries, social tags, and products in general. There are three approaches(Collaborative Filtering, Content-based Filtering, Hybrid recommender systems) for recommender system.
Natural Language Processing
Natural language processing(NLP) is a field of computer science, artificial intelligence, and computational linguistics concerned with the interactions between computers and human (natural) languages and, in particular, concerned with programming computers to fruitfully process large natural language corpora.
Text Mining: Text mining, also referred to as text data mining, roughly equivalent to text analytics, is the process of deriving high-quality information from text.
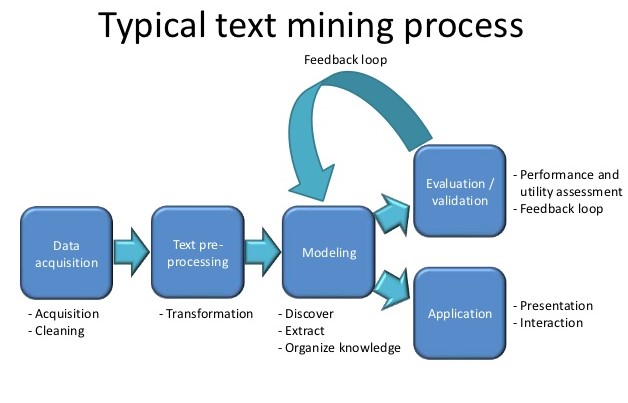
Sentimental Analysis: Sentiment analysis (sometimes known as opinion mining or emotion AI) refers to the use of natural language processing, text analysis, computational linguistics, and biometrics to systematically identify, extract, quantify, and study affective states and subjective information.
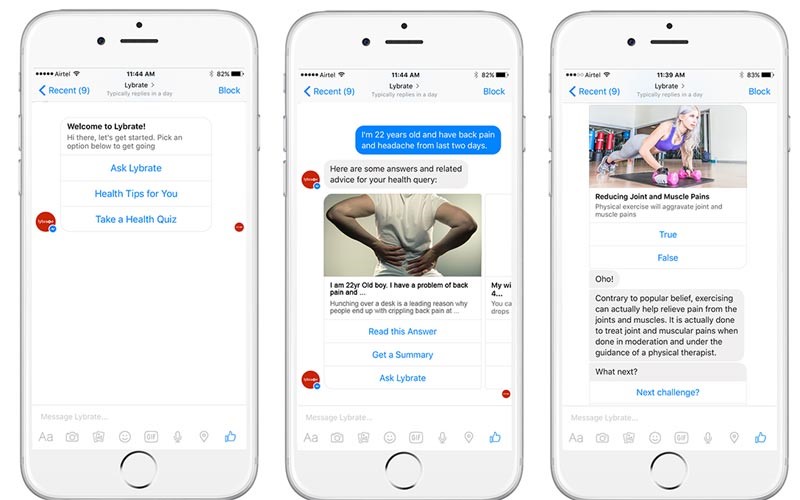
Chatting Bot: A chatbot (also known as a talkbot, chatterbot, Bot, chatterbox, Artificial Conversational Entity) is a computer program which conducts a conversation via auditory or textual methods.